# Create a corpus from the textcorpus <-Corpus(VectorSource(text))# Convert to lowercase, remove punctuation, and remove numberscorpus <-tm_map(corpus, content_transformer(tolower))corpus <-tm_map(corpus, removePunctuation)corpus <-tm_map(corpus, removeNumbers)# Convert the corpus to a term-document matrixtdm <-TermDocumentMatrix(corpus)# Convert the tdm to a matrix and calculate the frequency of each termm <-as.matrix(tdm)v <-sort(rowSums(m), decreasing=TRUE)# Create a dataframe of the most frequent terms and their frequenciesdf <-data.frame(word =names(v), freq = v)
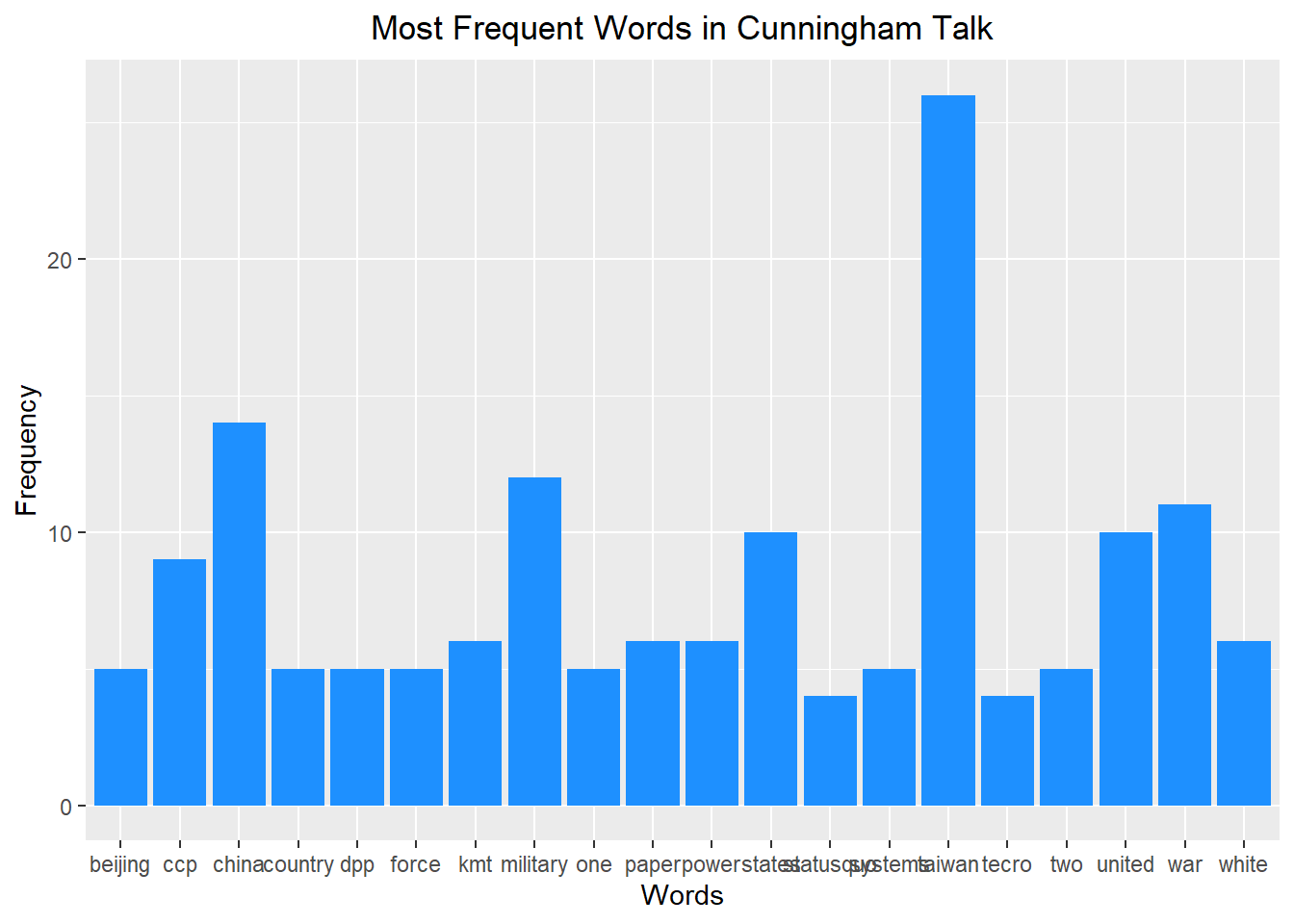
# Create a corpus from the textcorpus <-Corpus(VectorSource(text))# Convert to lowercase, remove punctuation, and remove numberscorpus <-tm_map(corpus, content_transformer(tolower))corpus <-tm_map(corpus, removePunctuation)corpus <-tm_map(corpus, removeNumbers)# Convert the corpus to a term-document matrixtdm <-TermDocumentMatrix(corpus)# Convert the tdm to a matrix and calculate the frequency of each termm <-as.matrix(tdm)v <-sort(rowSums(m), decreasing=TRUE)# Create a dataframe of the most frequent terms and their frequenciesdf <-data.frame(word =names(v), freq = v)# Create a bar chart of the top 20 most frequent termsggplot(head(df, 20), aes(x=word, y=freq)) +geom_bar(stat="identity", fill="dodgerblue") +xlab("Words") +ylab("Frequency") +ggtitle("Most Frequent Words in Cunningham Talk") +theme(plot.title =element_text(hjust =0.5))